
Par Laure Belot Publié le 2 mars 2020
DÉCRYPTAGES
Ces données, transcendées par l’intelligence artificielle, vont façonner la médecine de demain. Comment sont-elles protégées, partagées, monnayées ? Quelle place pour la France face aux géants du numérique ?
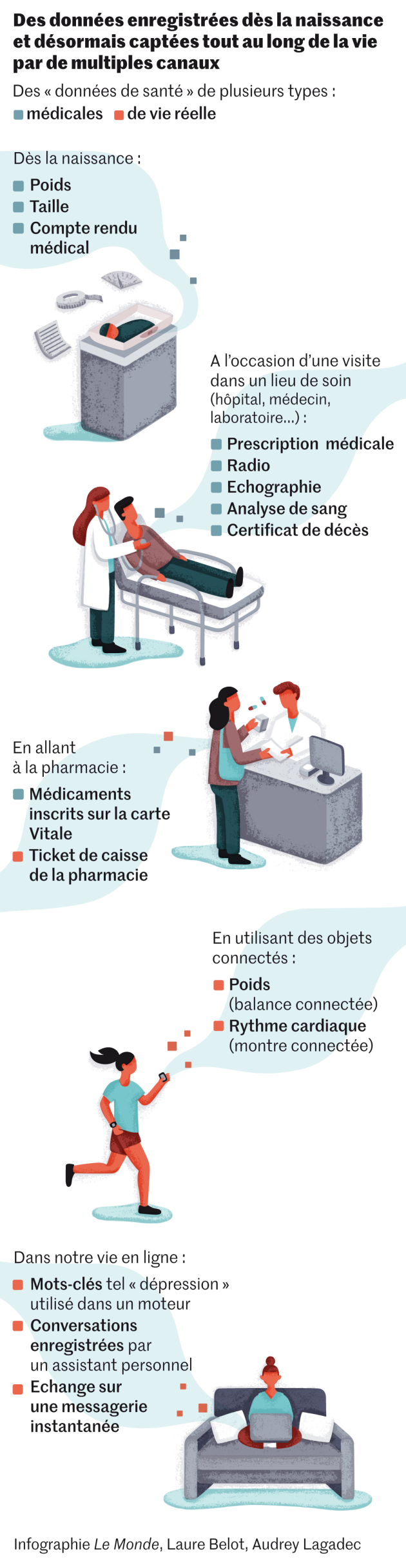
Nous sommes tous concernés mais le phénomène est tellement discret qu’il est difficile d’en prendre la pleine mesure. La planète est devenue, en quelques années, une gigantesque chambre d’enregistrement où une multitude d’informations relatives à notre santé, que nous soyons malade ou bien portant, sont stockées et potentiellement analysées par des algorithmes dont la puissance et l’intelligence ne cessent de croître.
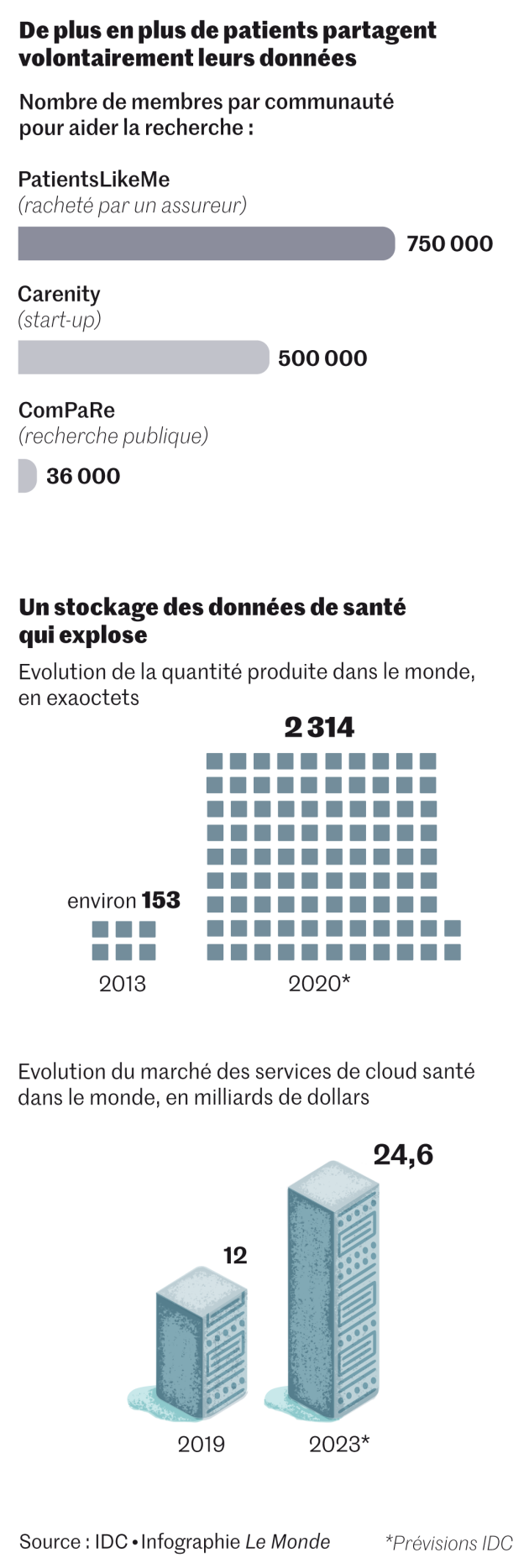
Selon l’article « Sizing up big data » (« dimensionner les données massives ») publié dans Nature Medecine de janvier, ces données de santé représentent un volume en croissance exponentielle, qui a plus que décuplé depuis 2013 : il s’agit tout autant de renseignements médicaux classiques – provenant de médecins, d’hôpitaux et de laboratoires… – que d’indicateurs captés dans la vie réelle, hors circuit médical – tels le rythme cardiaque mesuré par une montre, l’indice de masse corporelle calculé par une balance connectée ou le nombre de pas enregistrés par une application smartphone… Certaines de ces informations sont d’ailleurs captées sans que nous en ayons pleinement conscience.
« Le domaine du suivi de la santé, au-delà même de la maladie, explose littéralement, constate le médecin et biologiste Pierre Corvol, président de l’Académie des sciences. On voit se développer dans la société un désir de rester en forme pour profiter de la vie ou se conformer à l’image idéale de quelqu’un de performant. Cela a induit ces dernières années une activité commerciale phénoménale qui repose sur l’accessibilité des données massives de santé et de bien-être et leur traitement par des algorithmes d’intelligence artificielle [IA]. »
A partir de 1947, une étude épidémiologique pionnière, lancée par l’école de santé publique d’Harvard, a suivi des milliers d’habitants de la ville américaine de Framingham (Massachusetts) : tension artérielle, cholestérol, tabagisme… avaient alors été mesurés régulièrement pour appréhender le risque cardio-vasculaire devenu à l’époque la première cause de mortalité au monde. « Nous avions alors des hypothèses scientifiques et des objectifs médicaux pour une étude dont la connaissance bénéficierait à tous », explique Pierre Corvol. La « cohorte de Framingham » existe toujours, mais « nous sommes passés dans un autre monde », constate-t-il.
Un demi-siècle plus tard, sur une planète de plus en plus connectée, les acteurs traditionnels de la santé – infirmiers, médecins, hôpitaux, laboratoires – continuent à produire et à analyser des données médicales, désormais numérisées, à des fins de soins et de recherche, pour faire avancer la connaissance scientifique mondiale.
Mais une multitude de nouveaux acteurs économiques, industriels ou de services, start-up ou grands groupes, s’intéressent à ces données et y voient, dans un monde vieillissant et de plus en plus peuplé, des débouchés commerciaux prometteurs. Avec notamment une percée très remarquée d’Amazon et de Google, dont les capacités informatiques et la puissance financière sont hors du commun.
Les données de santé se retrouvent même dans la rubrique des faits divers, comme en novembre 2019, lorsque le CHU de Rouen a été victime d’une cyberattaque quelques semaines après les hôpitaux d’Issoudin (Indre), Delafontaine à Saint-Denis (Seine-Saint-Denis), de Condrieu (Rhône) et les 120 établissements du groupe Ramsay-Générale de santé.
« Le potentiel de ces données est énorme et suscite les convoitises, commente la juriste Hélène Guimiot-Bréaud, chef du service de la santé à la Commission nationale de l’informatique et des libertés (CNIL). La médecine de demain ne sera pas basée uniquement sur de nouvelles molécules mais aussi sur une personnalisation des traitements rendue possible par toutes les informations détenues sur les personnes. »
Cette transformation accélérée du paysage de la santé, des Etats-Unis à la Chine, qui investit massivement dans l’IA, suscite désormais un débat dans les instances scientifiques internationales. « L’usage de l’IA avec en corollaire la collecte des données est désormais un sujet suffisamment fort et évolutif pour nécessiter des mises au point régulières entre les différentes académies des sciences du G7 », explique Pierre Corvol.
Une réunion d’approfondissement « IA et santé » a été organisée en septembre 2019 à Ottawa après le G7 sciences en France. Les académies des sciences devraient continuer leur réflexion sur ce sujet lors d’une réunion en mars à Washington. Cinq questions pour faire le point…
1. Qu’entend-on par « données de santé » ?
Depuis sa naissance, une personne génère des « données de santé », souvent à son insu. Cela commence par son poids et sa taille de nourrisson, les remarques écrites par la sage-femme, un cliché annoté par un radiologue… Des chiffres, des textes, des images.
Cette production d’information continue au cours de la vie, qu’un adulte utilise sa carte Vitale à la pharmacie, reçoive le compte rendu d’un médecin, fasse une échographie. Même à sa mort, un certificat de décès renseigné par un médecin est produit. Ces chiffres, textes et images sont désormais la nourriture des algorithmes d’IA, programmes informatiques qui cherchent à donner un sens à ces informations massives et disparates.
Les arrivées du Web, du smartphone, des réseaux sociaux et des objets connectés – montres, balances, assistants personnels… il y a une trentaine, quinzaine et dizaine d’années – continuent à apporter plus de chiffres, de textes, d’images et même de sons, dont certains peuvent être en lien avec notre état de santé ou de bien-être. Comme des recherches sur une pathologie faites sur un moteur de recherche, une discussion sur une maladie avec un ami sur WhatsApp, une conversation intime à domicile captée par un assistant personnel…

Pour englober ces usages hétéroclites et cette aspiration récente d’informations personnelles tous azimuts, la définition d’une « donnée de santé » choisie par le Règlement général de protection des données européen (RGPD), en application depuis mai 2018, « est très large », rappelle Hélène Guimiot-Bréaud.
Une donnée de santé peut ainsi l’être classiquement « par nature » (si elle est issue du corps médical) mais aussi « par croisement » : des achats réguliers de « junk food » et un nombre très faible de pas réalisés par jour sont des informations indépendantes qui, croisées informatiquement, peuvent donner une indication sur un état de santé.

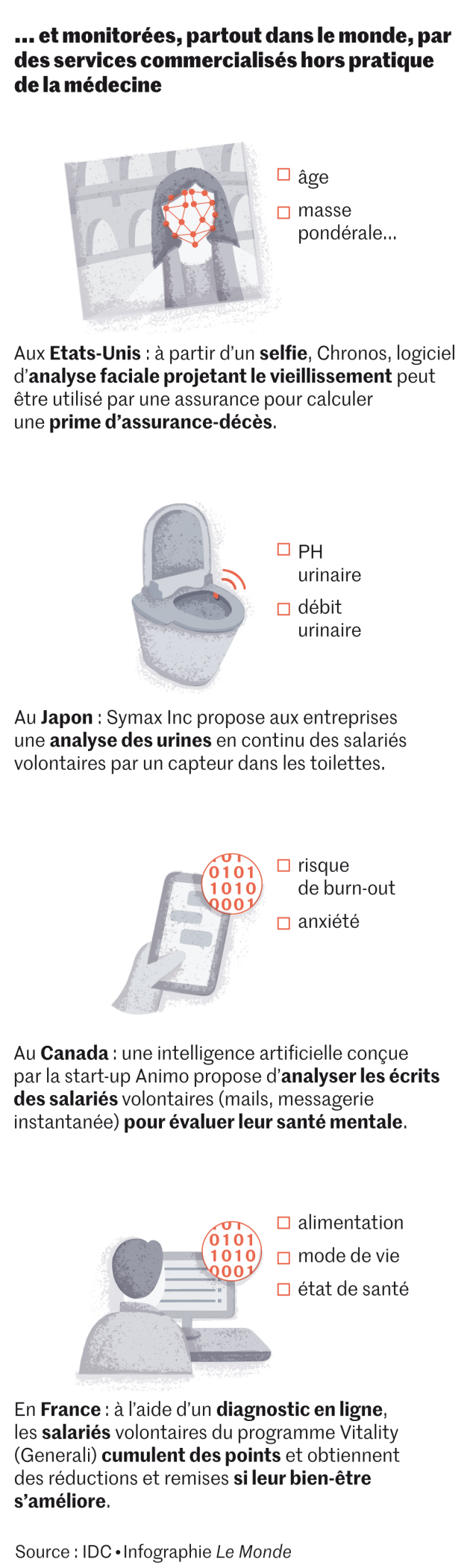
Le RGPD inclut également les données dites « par destination » tel un simple selfie, qui n’est pas directement lié à l’état de santé mais qui peut être utilisé aux Etats-Unis, par exemple, par une société d’assurances pour estimer, à l’aide d’un logiciel d’analyse faciale projetant le vieillissement, une prime d’assurance-décès.
2. Comment ces données sont-elles protégées en France ?
Une multitude de pratiques autour des données de santé – échange contre service ou argent par exemple – existant aux Etats-Unis ou dans certains pays asiatiques ne seraient pas autorisées en France, où l’arsenal législatif est plus contraignant. Dans le droit français, les données de santé, considérées comme la continuité du corps tel le sang, ne peuvent ni être cédées, ni être vendues. Le RGPD renforce encore leur encadrement.
« Comme les origines ethniques ou les opinions politiques, les données de santé sont dites “sensibles” et leur traitement, par principe, est interdit, sauf exception des situations qui peuvent être spécifiques à chaque pays », indique Hélène Guimiot-Bréaud. Ainsi, en France, le législateur a décidé « que les traitements ayant une finalité d’intérêt public, notamment à des fins de recherche, peuvent utiliser des données de santé après autorisation de la CNIL. »
Autre exception possible, une entreprise peut les utiliser si elle a reçu le consentement « libre, éclairé, spécifique et univoque » d’un usager. « Il faut cependant que la demande ait été très claire, précise la juriste. Certaines start-up numériques nous disent que ce consentement est implicite dans les conditions générales d’utilisation, souvent illisibles d’ailleurs, qu’ils font signer à leurs utilisateurs. Ce n’est pas conforme au RGPD. »
Les recours en cas d’abus sont possibles. Si un citoyen a donné son accord pour l’utilisation de ses données de santé dans des conditions précises, il peut saisir la CNIL « si ces conditions changent sans qu’il en ait été informé », détaille Mme Guimiot-Bréaud.
Aux Etats-Unis, le rachat en juillet 2019 et par l’assureur UnitedHealth – un repreneur chinois était aussi sur les rangs – de la communauté « PatientsLikeMe », créée par la famille d’un malade et rassemblant les données volontairement partagées par 750 000 autres malades voulant faire avancer la recherche, a créé un fort émoi. Le RGPD étant extraterritorial, la CNIL pourrait potentiellement être saisie par tout Français de cette communauté. « Nous n’avons cependant pas reçu de demandes en ce sens, précise la juriste. Peut-être parce que peu de citoyens sont au courant de cette possible démarche. »
3. Qu’est-ce que leur analyse va changer pour notre santé ?
La façon dont nous nous soignons va être bouleversée. La médecine dite « curative », approche qui a contribué à un allongement de la durée de vie d’une trentaine d’années depuis le début du XXe siècle en Europe, va se juxtaposer à une médecine préventive et de plus en plus personnalisée. Cela, à l’aide des textes, images, chiffres relatifs à des historiques de vie et de soins qui vont « entraîner » des algorithmes d’IA pour aider au diagnostic et même traiter des patients.
« Dès aujourd’hui, l’IA fait beaucoup mieux que des médecins, y compris spécialistes, pour analyser les images de la peau, de l’œil, des images radio, etc. », atteste le professeur Philippe Ravaud, qui dirige le laboratoire CRES d’épidémiologie et de statistiques.
Les résultats s’accélèrent. En 2017, une IA a fait aussi bien que des dermatologues pour déceler des cancers de la peau. En 2018, l’agence américaine du médicament (FDA) a accepté pour la première fois qu’une IA pose un diagnostic de rétinopathie diabétique, grave affection de l’œil, sans supervision par un médecin.
« On va pouvoir identifier de manière plus précise les rechutes de malades chroniques avant leurs manifestations classiques »
En France, depuis février 2019, six cliniques utilisent – et dix testent – le logiciel d’IA de la start-up TheraPanacea pour identifier les organes à risque – autour d’une tumeur par exemple – à ne pas irradier lors d’une radiothérapie. « Une validation d’un médecin est toujours nécessaire, mais cet algorithme est certifié classe D, pour dispositif médical de traitement car, mal utilisé ou mal interprété, il peut avoir un impact sur la vie du patient », explique le chercheur Nikos Paragios, fondateur de la start-up, dont un des actionnaires est l’institut Gustave-Roussy, grand centre de la région parisienne spécialisé dans le traitement du cancer.
« L’espoir est de créer un système nationalement plus équitable où tout patient puisse être soigné à l’identique, même si un médecin dans une petite ville n’a pas la même expertise que dans un centre spécialisé de pointe », indique cet ancien directeur de laboratoire en IA appliquée à la santé, à Centrale Paris.
D’autres promesses de l’IA se précisent. « On va pouvoir identifier de manière plus précise les rechutes de malades chroniques avant leurs manifestations classiques », affirme Philippe Ravaud. Il sera aussi possible « d’accompagner en temps réel des patients – avec le “Just-in-Time Adaptive Intervention (JITAI)” – afin de modifier des comportements à risque et adapter par exemple le traitement par insuline de personnes diabétiques ou l’alimentation d’un malade pour modifier son microbiote ».
Déjà, en Allemagne, poursuit-il, « l’utilisation des robots conversationnels (chatbots), outils de psychothérapie basés sur de l’IA est remboursée par la Sécurité sociale ». Pour accélérer la recherche sur les maladies chroniques, cet épidémiologiste a lancé la communauté ComPaRe, où 36 000 patients volontaires partagent, pour la recherche publique, leurs données de « vie réelle » non collectées par des médecins. « La prochaine étape est de relier ces données avec des données hospitalières et d’autres, médico-administratives. »
4. Qui d’autre que le corps médical s’y intéresse ?
Une multitude d’acteurs économiques, nouveaux ou plus traditionnels, se positionnent, avec un appétit grandissant sur ce que l’on peut désormais appeler le « marché des données de santé », que celles-ci soient issues de la vie réelle ou plus classiquement de protocole de recherche clinique.
De petites sociétés numériques proposent des applications qui captent des données moyennant des services pour mieux dormir, gérer son poids, suivre son cycle d’ovulation… « Ces acteurs nouveaux surfent sur le marché du bien-être, moins contrôlé par la législation européenne que celui de la santé, alors qu’une grande partie des promesses annoncées ne sont pas prouvées scientifiquement », regrette Pierre Corvol, président de l’Académie des sciences.
Des communautés privées de patients se développent, telle Carenity, qui rassemble « 500 000 malades et aidants dans le monde, dont 150 000 en France », annonce son dirigeant Michael Chekroun. Le service de réseau social pour les patients, accessible par une application en cinq langues, est gratuit et l’entreprise « vend des enquêtes faites auprès de membres volontaires sur des questions posées par des laboratoires pharmaceutiques, de fabricants de dispositifs médicaux et d’organismes de recherche, à partir de résultats anonymes et agrégés », précise l’entrepreneur.
Désormais également, des associations de malades développent des services auprès d’industriels ou de laboratoires pour proposer des prestations de recueil de données de membres volontaires.
Pour débusquer les données les plus fiables dans ces sources multiples, des intermédiaires appelés « CRO » (pour « Clinical Research Organisation ») travaillent pour le compte de clients multiples, tout autant « des laboratoires que des fabricants de pacemakers ou de balances connectées », énumère Sébastien Marque, responsable des données de vie réelle de IQVIA. Cette société a par exemple constitué « un Entrepôt propre de données de santé (EDS) qui s’enrichit, chaque semaine, des informations issues des tickets de caisse d’environ 40 % des pharmacies en France ».
Cette quête – que l’on retrouve dans le monde entier – des données de santé bien renseignées a une finalité économique simple : entraîner des logiciels d’IA avec le maximum d’informations sur des citoyens (malades ou bien portants) afin d’arriver, avant les autres concurrents, à proposer services ou produits inédits.
Aux Etats-Unis, « un grand laboratoire a tenté, en 2017, d’utiliser des données de vie réelle pour remplacer le groupe témoin dans un essai clinique de phase 3 [juste avant l’autorisation de mise sur le marché] en oncologie. Le médicament, qui a connu un développement accéléré et moins coûteux, a été approuvé par la FDA en 2018. Depuis, tous les autres laboratoires pharmaceutiques s’y mettent », constate Robert Chu, cofondateur de la start-up Embleema.
Cette nouvelle plate-forme propose aux citoyens de mettre à disposition de chercheurs leurs données médicales et de vie réelle moyennant rémunération (uniquement pour les Etats-Unis). Le tout en utilisant une nouvelle solution numérique, la blockchain, « technologie décentralisée permettant un partage sécurisé et vérifiable », affirme le cofondateur.
De nouveaux partenariats se nouent, tel celui des laboratoires pharmaceutiques Novartis, Otsuka, Pfizer, Sanofi avec Verily, filiale de Google, en mai 2019 pour avoir accès à des plates-formes de données de santé provenant de sources multiples afin d’accélérer leur recherche clinique et codévelopper des outils. « Les grands laboratoires cherchent à adopter une approche “beyond the pill” (au-delà de la pilule), constate le professeur Philippe Ravaud. C’est-à-dire ne plus vendre seulement des médicaments mais proposer des solutions et outils de prévention, de soins et d’après-traitement. »
« Les Gafam ne peuvent pas générer de la donnée profonde de santé comme un CHU, mais ils négocient massivement pour en acquérir »
Au cœur de cette course, les Gafam (Google, Amazon, Facebook, Apple, Microsoft) se développent à une vitesse sidérante. Ces entreprises proposent tout d’abord des services de cloud pour héberger ces données qui prennent de plus en plus de place – comme Microsoft, qui héberge les données de la plate-forme française Health Data Hub.
Elles développent et achètent aussi des applications ou objets connectés captant des données – telle l’Apple Watch ou l’application Fitbit, rachetée par Google 2,1 milliards de dollars (1,88 milliard d’euros) en novembre 2019 à la barbe de Facebook. Mais elles cherchent aussi désormais à se positionner sur la production de connaissances scientifiques.
Telle la publication, dans Nature du 1er janvier, de l’étude très remarquée sur la lecture très efficace d’une mammographie par une IA pour dépister des cancers du sein (International evaluation of an AI system for breast cancer screening). Une étude signée par vingt et un chercheurs du groupe Alphabet-Google (Google Health, DeepMind, Verily) et dix chercheurs de sept centres de recherche d’imagerie et d’hôpitaux spécialisés sur le cancer américains et britanniques (de Stanford à l’Imperial College, de Northwestern Medecine à Cambridge).
A quelle fin ? Le professeur Philippe Ravaud, également professeur associé à l’université Columbia (Etats-Unis), voit bien ces géants se développer sur les outils « de diagnostic, de pronostic et même de prise en charge des malades sans que ce soient forcément des médicaments ». Il poursuit : « Les Gafam ne peuvent pas générer de la donnée profonde de santé comme un CHU, mais ils négocient massivement pour en acquérir. Ils ont de l’argent, de la matière grise et une capacité à investir quelle que soit la prise de risque. Sur vingt projets, peut-être qu’un seul marchera, mais il suffira à financer tout le reste. »
5. Quels sont les points d’ombre en France ?
Pour espérer obtenir des résultats fiables avec des algorithmes d’IA, « il faut beaucoup de données pour éviter les biais statistiques et pouvoir déceler des effets subtils », explique la chercheuse Camille Maumet, de l’Inria Rennes, qui met au point des méthodes pour comprendre, par exemple, sur des images cérébrales ce qui se passe avant que les stigmates d’une maladie de type Alzheimer n’apparaissent.
Les équipes avec lesquelles Camille Maumet collabore utilisent des données « de très grande qualité issues de la base UK Biobank, qui a presque 50 000 images de cerveaux renseignées, ce qui est inégalé ailleurs », précise-t-elle. UK Biobank, lancée en 2005 par l’épidémiologiste Sir Rory Collins pour suivre sur trente ans les données de santé (génétiques, biologiques, d’imagerie…) de 500 000 citoyens britanniques de 40 à 69 ans, est devenue une référence mondiale de la recherche.
Le chantier est immense. Pour l’instant seules les données médico-administratives sont rassemblées dans un fichier unique
C’est là que le bât blesse en France. « Nous ne sommes pas en avance », reconnaît Stéphanie Combes, responsable depuis deux ans du Health Data Hub, projet très ambitieux qui veut créer une plate-forme pour la recherche avec « un catalogue des bases de données les plus prometteuses en France ». Le chantier est immense.
Pour l’instant, seules les données médico-administratives (SNDS) – registres de l’Assurance-maladie, inscriptions hospitalières… – sont rassemblées dans un fichier unique. Les données de soins, elles, sont dispersées dans une multitude de lieux (CHU, laboratoires de ville, centres de recherche, sociétés savantes…) et sous de multiples formats informatiques.
« Les pouvoirs publics ont laissé, au début des années 2000, le système de soins français s’informatiser de façon indépendante et il ne s’est pas construit de façon harmonieuse », analyse Dominique Pon, directeur général de la clinique Pasteur de Toulouse, qui a été nommé fin 2018 responsable de la transformation numérique en santé par l’ancienne ministre, Agnès Buzyn. Le même scénario se reproduit pour la constitution actuelle des EDS sur le territoire. « Les différents CHU s’organisent comme ils le veulent, et ce n’est pas coordonné », note Stéphanie Combes. Difficile, dans ces conditions, que toutes les données puissent « se parler » informatiquement.

L’autre frein à la création de cette plate-forme n’est pas technique. Les CHU, par exemple, n’ont plus un représentant unique dans le projet. « La Fédération hospitalière de France [qui représente l’ensemble des CHU] ne nous a pas apporté pour l’instant de réponse concrète sur ce qu’on pouvait faire ensemble. Je rencontre actuellement des CHU et un groupe de travail va être lancé en mars », explique la responsable du Health Data Hub.
En cause ? « Le partage de la valeur créée et de la propriété intellectuelle liées à la mise à disposition de ces données, répond Stéphanie Combes. Certains CHU ou centres de recherche veulent que chaque société privée qui va accéder aux données contractualise avec eux et se mette d’accord sur un partage de la valeur créée. Nous pensons de notre côté qu’un retour sur investissement pour l’effort de la collecte est nécessaire, mais que cela ne doit pas forcément entraîner un contrat avec accès aux bénéfices potentiels. »
« Les pouvoirs publics sont dans leur rôle pour définir des règles éthiques à la française afin d’éviter toute logique marchande »
Le débat polarise. Dans le rapport « Données de santé : quelles valeurs pour les établissements de soins ? » publié en novembre 2019, le Healthcare Data Institute, un think tank cocréé par le groupe Orange, souligne qu’il « souhaite encourager les établissements de santé à se doter d’une stratégie d’exploitation de données ».
Selon Dominique Pon, cependant, « l’histoire de la valorisation des données de santé a un côté très malsain. Si on était dans un système où toute la santé était gérée par des organisations privées, cela pourrait se comprendre, poursuit-il. Mais nous sommes dans un système où tout – professionnels de santé, logiciels de santé, recherche – est financé par la solidarité nationale et administré par les pouvoirs publics, qui sont donc dans leur rôle pour définir des règles éthiques à la française afin d’éviter toute logique marchande. »
La situation actuelle crée des blocages. « Aujourd’hui, en France, on est obligé de passer un temps considérable à discuter sans être sûr d’avoir un jour accès aux données, constate le scientifique entrepreneur Nikos Paragios. En décembre 2019, nous sommes allés au Canada, au centre hospitalier de Montréal, pour avoir des données, car notre demande auprès d’un grand CHU en France, lancée en septembre 2019, ne donnait rien. Dès janvier nous recevions le document de partage de données du Canada. Alors que nous n’avons toujours pas reçu, à ce jour, de réponse française. »
Ces acteurs qui discutent de valorisation semblent oublier, poursuit l’entrepreneur, « que les données servent à l’apprentissage des algorithmes. Une fois cette phase terminée, les données ne servent plus et la valeur n’est plus là. » Les projets de recherche, privés ou publics, attendent des réponses rapides « car, comme nous sommes dans des domaines très nouveaux et concurrentiels, c’est la première offre mondiale de produit ou de service efficace qui récupérera le marché ».
« Nous allons inexorablement vers un modèle d’exploitation de plus en plus massive des données de santé car, dans un monde idéal, la promesse est extraordinaire pour le bien commun »
« Il n’existe pas tant de start-up spécialisées en données de santé en France, tout simplement parce que c’est un parcours du combattant pour y accéder, et qu’ensuite, elles doivent traiter ces données pour pouvoir les utiliser de manière moderne, estime l’ancienne data scientist Stéphanie Combes (Health Data Hub). Le premier dispositif médical intégrant de l’IA a été certifié au printemps 2018 par l’agence américaine du médicament et nous n’en avons pas en France. Si nous voulons rester sur un système de santé de pointe, et qui puisse bénéficier à tous, il faut impérativement que nous prenions ce virage-là. Après, ce sera trop tard. »
Pour Stéphane Grumbach, directeur de recherche à l’Inria et enseignant à Sciences Po Paris, le sujet revêt une dimension géopolitique. « Dans tous les secteurs d’activité, les données sont désormais gérées par de très grandes plates-formes, domaine dans lequel les Etats-Unis et la Chine, qui ont massivement misé sur des start-up pour les créer, sont très en avance. La santé ne va pas échapper à ce mouvement. Or il manque pour l’instant une plate-forme en France, tout l’enjeu est là, constate-t-il. Il est essentiel qu’il y ait de telles plates-formes en Europe, car celles-ci, avec leur logique, leurs valeurs et leurs normes, influeront fortement sur les politiques nationales de santé. » Le pouvoir des plates-formes « se voit déjà dans d’autres domaines, tel le droit du travail avec des acteurs comme Uber par exemple ».
« Nous allons, poursuit-il, inexorablement vers un modèle d’exploitation de plus en plus massive des données de santé car, dans un monde idéal, la promesse est extraordinaire pour le bien commun, le bien des personnes et des populations. Mais il se pose désormais des questions de souveraineté qui dépassent les seuls intérêts privé-public. Dépendre de plates-formes étrangères dans des domaines comme la santé ou l’éducation, c’est inhiber la capacité même de gouverner. »
Aucun commentaire:
Enregistrer un commentaire